Class 15: Graph Machine Learning 2#
Goals of today’s class:
Understand what embeddings are and how neural networks work at a high level.
Explain what makes graph neural networks different from other kinds of neural networks (i.e. how do they learn on network data?)
Iterate on an example neural network model to learn about what affects its performance.
Come in. Sit down. Open Teams.
Find your notebook in your /Class_15/ folder.
Embeddings and Neural Networks#
TL;DR: We often represent our data as vectors, but these vectors can get really, really long. They also tend to be sparse. By learning embeddings that more concisely represent our data, we can learn more meaningful patterns in our data.
Embeddings#
When we talk about making embeddings, we’re talking about representing our data points or objects in our dataset as meaningful vectors. In graphs, and in natural language, we could represent nodes and words as sparse vectors. These might look like the sparse rows in an adjacency matrix, or they might look like one-hot representations whose length is equal to the cardinality of a language’s entire vocabulary. Of course, representations like these aren’t very useful when we think about looking at questions of similarity or really any sort of machine learning applications.
Enter embeddings. Embeddings can result from dimensionality reduction techniques like principal component analysis (PCA), but nowadays, when we think about embeddings, we tend to think about vectors that are created via training a neural network model to do a task.
Neural Networks#
(this section borrows heavily from the coverage of ML in Bagrow & Ahn, section 16.2)
These can seem complicated to understand, but they, are at their heart, just doing a bunch of very parallelizable matrix operations. Here’s a picture of a simple feed-forward neural network, sourced from this handy Medium post.
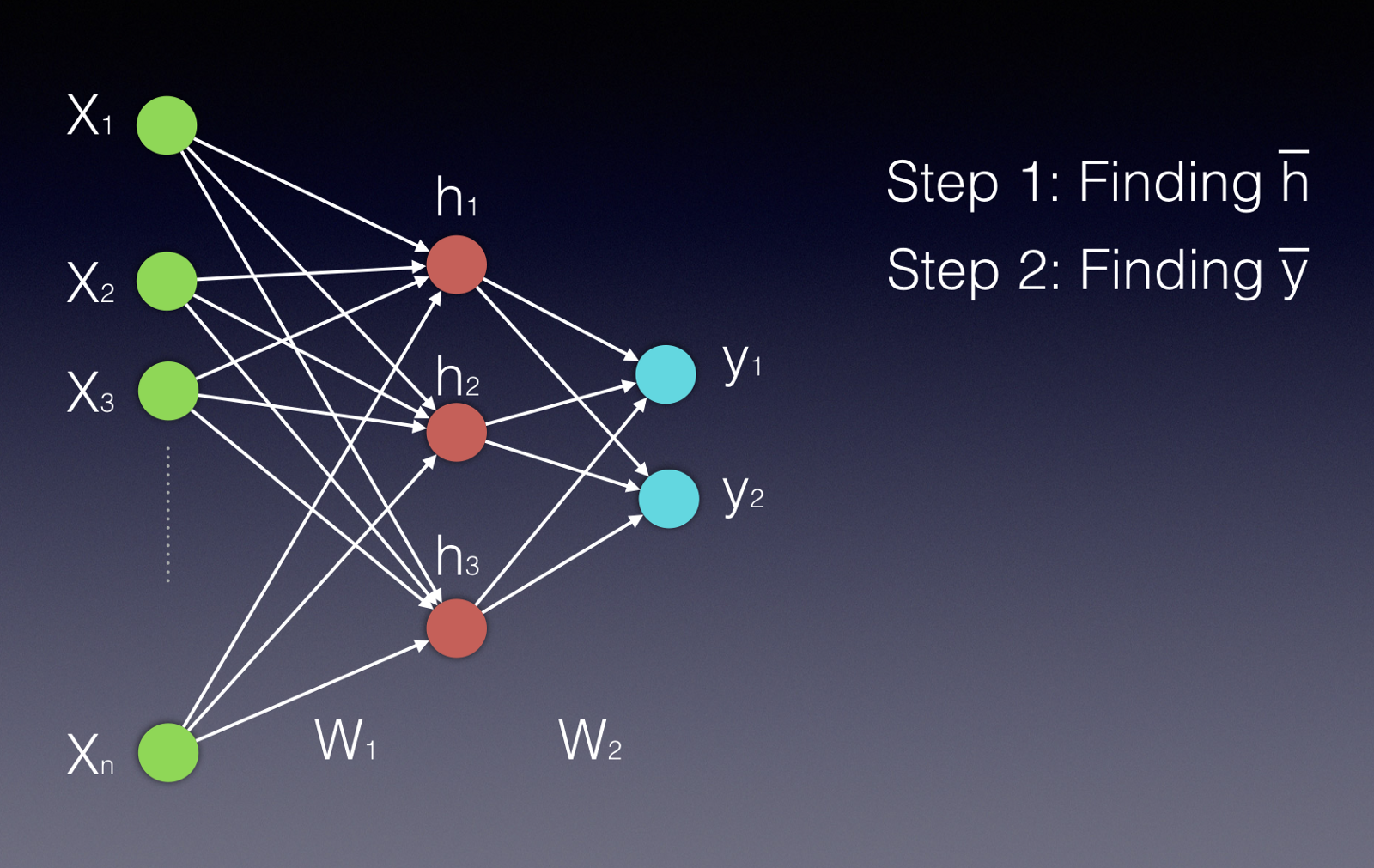
Neural networks consist of sets of units (neurons) arranged in a sequence of layers. When we talk about the architecture of a neural network, we’re talking about how the units are arranged, how many of them there are, how many layers we have, and the number of units per layer. In a fully connected feed-forward network, each unit in each layer is connected to all the nodes in the layer after it. First, the input nodes (the green ones) receive the input data (this could be attributes of a product, for example). Data moves through the network in the picture from left to right.
The output of a particular unit is the activation function of the weighted sum of its inputs (\(\sigma(\vec{w}^T \vec{x})\)), where \(\vec{w}\) is the weights of the inputs for that unit, and \(\vec{x}\) is the inputs coming from the previous layer. \(\sigma\) is the nonlinear activation function; in this case, we’re probably thinking of the sigmoid function (pictured below & sourced here), but other activation functions, like \(\tanh\), are possible as well (image sourced here).
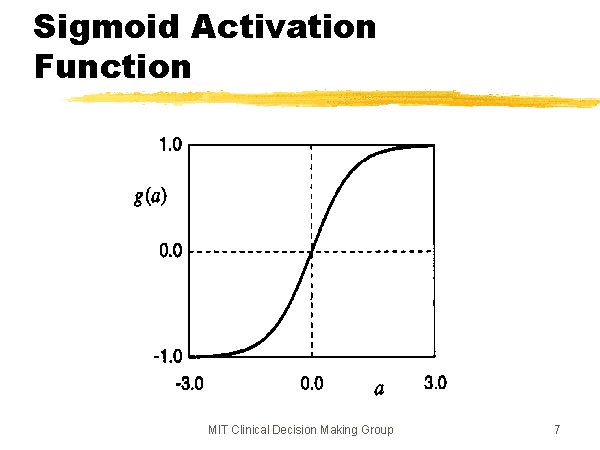
Neural networks can learn nonlinear patterns in data because of these nonlinear activation functions. If they only used linear activation functions, they would be learning the weights for a weighted piecewise linear function on their inputs. In other words, neural networks are powerful precisely because they have many built-in nonlinearities.
The outputs we get from each unit in the middle layer then are passed to the final layer, and then we compare the final layer’s output to our desired output. Maybe the \(\vec{y}\) outputs in the picture are probabilities of the product belonging to a particular class, for example. Our task is to use a loss function, of which there are many, to express how far off we are from our correct answer. Once we’ve done that, we can use an algorithm called backpropagation to nudge the weights (\(\vec{w}\)) towards values that would be closer to producing the desired label.
Our choice of loss function is important here; what works well for classifying products may be terrible for predicting flight prices, for example. For a more complete primer on loss functions, check out this blog post. Generally, your loss function and the tasks you’re setting up the neural network to learn will reflect what you want your neural network to do effectively. We might use a squared error loss function if we’re predicting flight prices, and we might use a cross-entropy loss function to quantify how incorrect our predictions are for a classifier. There are more complicated loss functions and task setups, one of which we’ll discuss in the next section.
*tovec#
Word2Vec#
Word2Vec was a pretty early natural language processing technique that was very exciting at the time. It trained a fairly simple neural network to do one of two tasks: Continuous Bag-of-Words (CBOW) or Skip-Gram. CBOW involves predicting which word is missing from a given context of surrounding words, and Skip-Gram involves doing the opposite: predicting the surrounding context given a specific word. The loss function here is cross-entropy loss; we use a softmax activation function to turn the outputs of the final layer into a probability distribution and then use cross-entropy loss to quantify how incorrect we were. Here’s some more info; the links are where we sourced our images for softmax and word2vec.

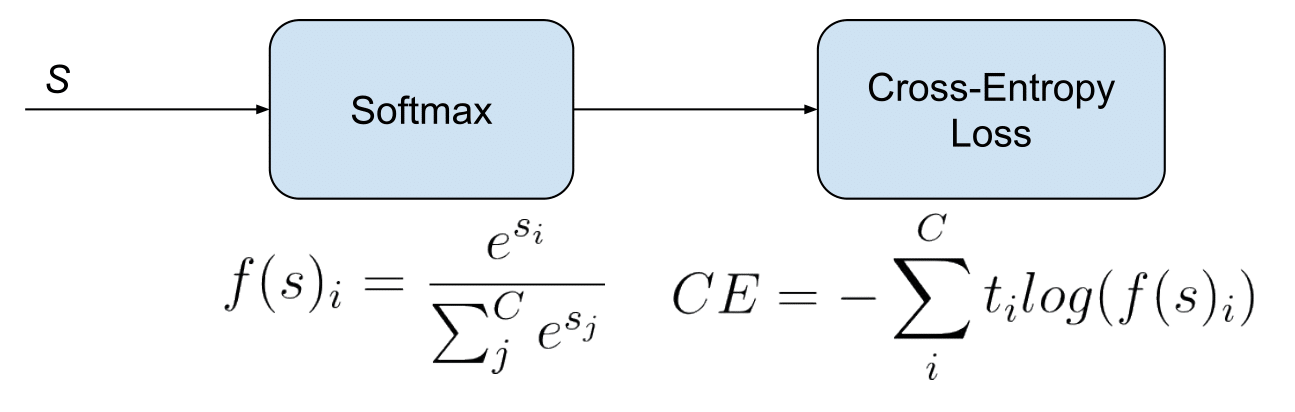
Node2Vec#
Node2Vec follows similar logic to Word2Vec. We do random walks through a network and treat these random walks like sentences. Then we can do CBOW or Skip-Gram to obtain node embeddings. At each iteration, Node2Vec samples \(n * r\) random walks (with \(r\) walks starting at each node). It has hyperparameters that influence how much we revisit nodes (\(p\)) and how much we favor visiting close nodes versus nodes that are further from where we started (\(q\)).
When people around the time of Node2Vec were thinking about building node embeddings, they tended to consider homophily (nodes that are linked are likely to be similar) or structural equivalence (nodes with similarly structured neighborhoods are likely to be similar). Random walks that are closer to depth-first search tend to get further away from their start node, so they’ll have a better sense of the community structure of a given graph and we’ll get more information about node homophily (in theory). However, longer-range dependencies can be harder to make sense of and more complicated. If we instead do something more like a breadth-first search, we’re thinking more about structural equivalence – whose neighborhoods looks similar? This isn’t likely to explore more distant parts of the graph, and nodes will repeat themselves a lot in a given walk. So Grover & Leskovec structured their random walks with hyperparameters \(p\) and \(q\) that allow us to figure out where on the BFS - DFS spectrum we want to end up.
Our non-normalized probability \(\alpha(v, x) * w(v, x)\) of visiting a given node \(x\) after having visited \(v\) in the previous step is:
where \(d(i, j)\) is the number of hops between node \(i\) and node \(j\).
Here’s an image from the original Node2Vec paper of the different outcomes of Node2Vec on a network generated from the novel Les Misérables with hyperparameter settings that lean more towards prioritizing homophily (closer to DFS) and structural equivalence (closer to BFS).
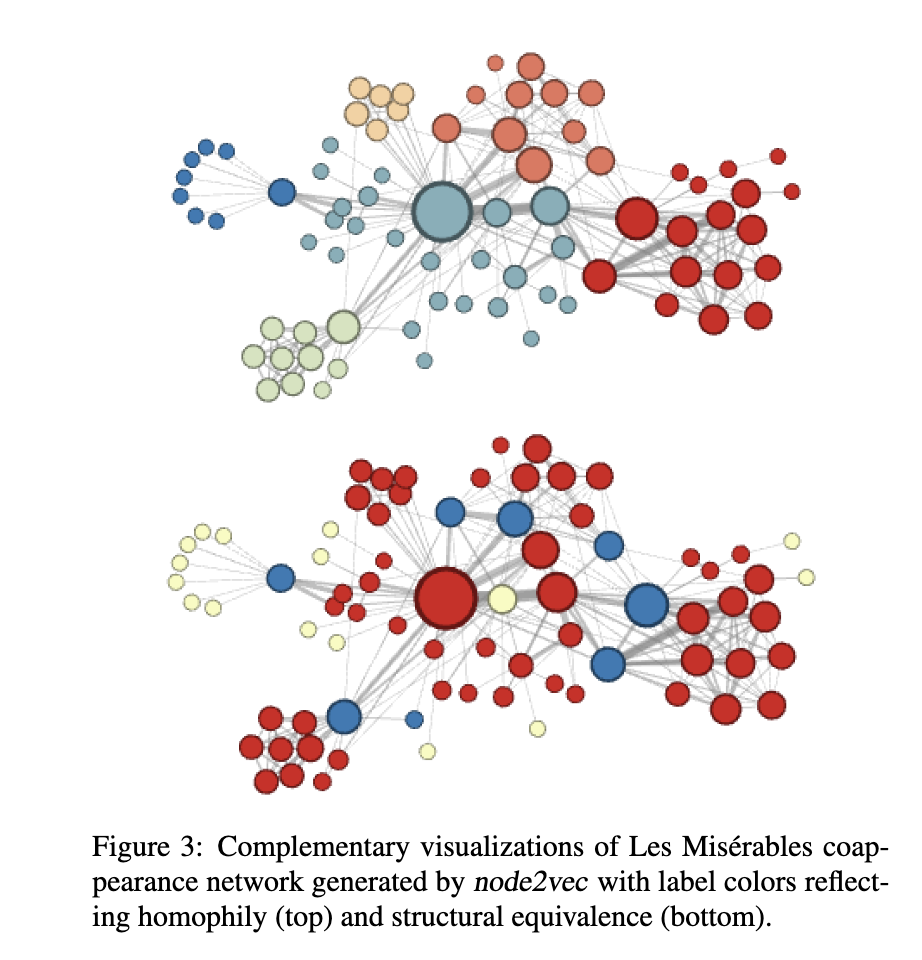
Node2Vec also incorporates negative sampling, where we only look at the outputs for a couple nodes that definitely shouldn’t be in an input node’s neighborhood. We make sure our outputs for those nodes are zero and do backpropagation accordingly; it’s possible to tune how many negative samples we do for each positive sample. Adding negative samples improves our model’s performance, and it’s relatively cheap to do because we’re not tuning all the weights in the model at once.
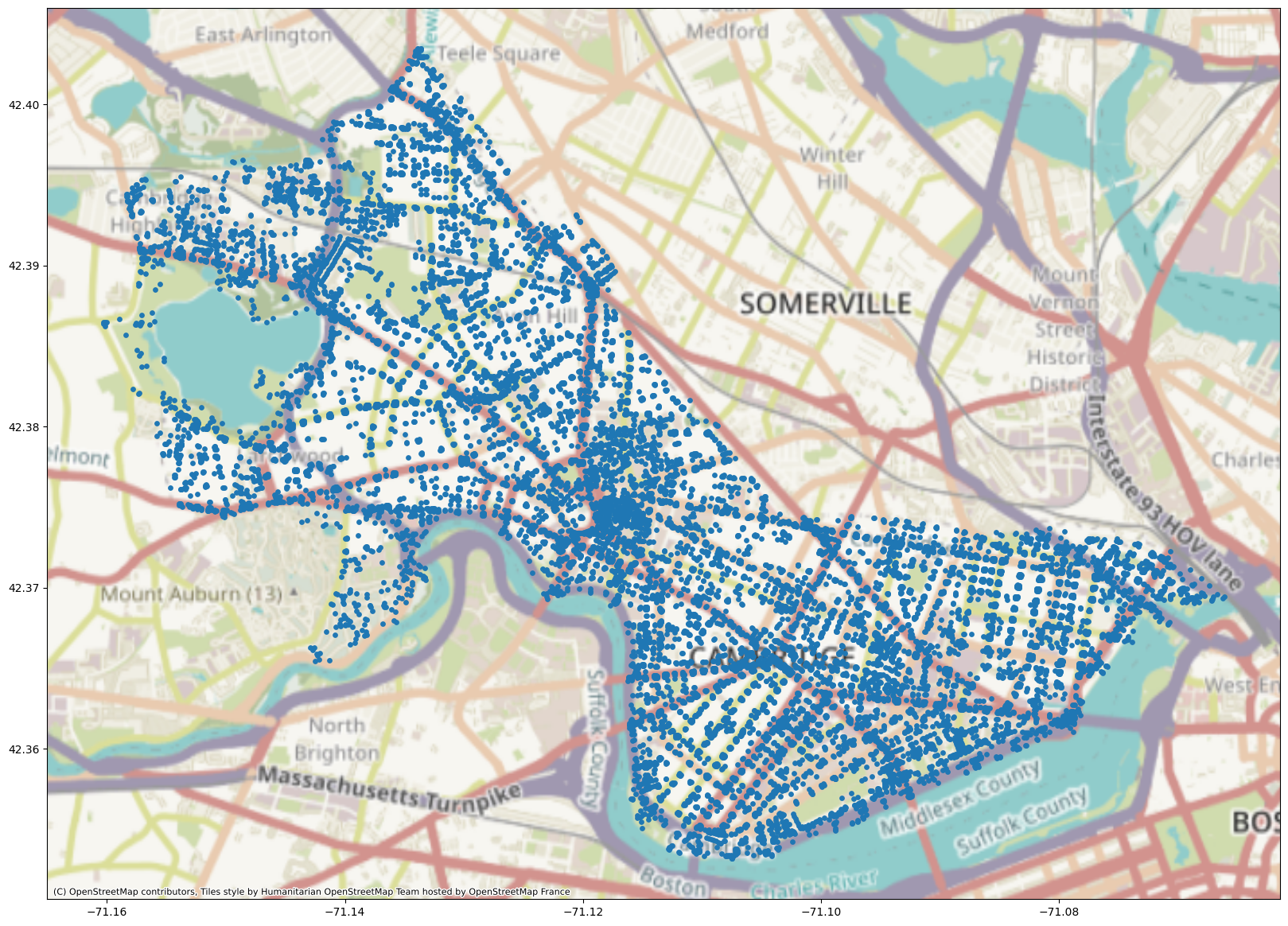
We can do a version of Node2Vec where we’re making embeddings for embeddings’ sake, as we do in this setting, or we can try to train a classifier on Node2Vec embeddings to predict labels for nodes. Here we’re going to train Node2Vec (without node or edge labels) on the Cambridge, MA road network dataset. Let’s see what happens! Our training code is borrowed from pytorch-geometric and can be found here.
Notice that since we’re just trying to build embeddings to demonstrate Node2Vec’s capabilities, we’re not holding out any data right now. Node2Vec does sample negative examples as it trains, so that the model learns which contexts or nodes are correct and builds accurate embeddings. If we were training a link prediction model with Node2Vec, as you can choose to do at the end of this class, we would at minimum hold out some fraction of links to make sure our embeddings were of good quality and useful for the downstream link prediction task.
import osmnx as ox
from shapely import Point
import geopandas as gpd
import matplotlib.pyplot as plt
import contextily as cx
plt.rcParams['figure.figsize'] = (20, 20)
S = 15
G = ox.graph_from_place('Cambridge, Massachusetts, United States')
points = [Point((G.nodes[i]['x'], G.nodes[i]['y'])) for i in G.nodes]
geo_df = gpd.GeoDataFrame(geometry = points, crs='EPSG:4326')
plot = geo_df.plot(markersize=S)
cx.add_basemap(plot, crs=geo_df.crs.to_string())
On Training Neural Networks#
We’re going to use pytorch and pytorch-geometric to make our neural network construction relatively pain-free. Pytorch is a widely used package for building & training neural networks. It’s compatible with CUDA-capable GPUs (CUDA is Nvidia’s deep learning framework that makes doing ML in GPUs possible).
GPUs#
GPUs, or graphical processing units, are great at doing a lot of tiny calculations at the same time. This is different from CPUs, which are good at doing a few big calculations at once (this is a vast oversimplification, but it’s good enough for an overview). Neural networks do a lot of vector and matrix multiplication (Remember those dot products from before? How do they scale up to a whole layer?) which is very easy to parallelize on a GPU. We’re using GPUs today to speed up our Node2Vec training, which would be pretty slow on a CPU.
Hyperparameters#
In the neural network context, Hyperparameters are parameters that control how we find the neural network’s weights (the non-hyper parameters, or just plain parameters). Examples of hyperparameters are learning rate, number of layers, choice of optimizer, layer size, and activation function(s). Finding good hyperparameters can take a lot of time, depending on the number and types of hyperparameters you’re playing with; platforms like Weights and Biases have sprung up to help developers tune hyperparameters for their neural network models.
import torch
import sys
from torch_geometric.data import Data
from torch_geometric.nn import Node2Vec
# giving nodes new indices, as Node2Vec expects indices to start at 0 and end at |N| - 1.
for idx, node in enumerate(G.nodes):
G.nodes[node]['idx'] = idx
# build a tensor with all the edges in the graph.
my_tensor = []
for e in G.edges:
my_tensor.append([G.nodes[e[0]]['idx'], G.nodes[e[1]]['idx']])
# actually convert it to a torch Tensor --
# this has to be a torch datatype or it will not play nicely with the GPU.
edge_list = torch.Tensor(my_tensor).T.to(torch.long)
# checking if we have a CUDA-capable GPU available.
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
# constructing our Node2Vec model and giving it our edge list as input.
# note that you can tweak all of these parameters!
model = Node2Vec(
edge_list,
embedding_dim=32,
walk_length=20,
context_size=10,
walks_per_node=10,
num_negative_samples=1,
p=1.0,
q=1.0,
sparse=True,
).to(device)
# we have 2 CPU cores requested by default in our sessions.
# (we use CPU cores to load our data).
num_workers = 2 if sys.platform == 'linux' else 0
# we use batches to work through our dataset without overloading the GPU.
loader = model.loader(batch_size=128, shuffle=True, num_workers=num_workers)
# you can play with optimizer choices; Adam and AdaGrad are popular choices.
optimizer = torch.optim.SparseAdam(list(model.parameters()), lr=0.01)
for epoch in range(1, 51): # an epoch refers to going over all the data once
model.train() # set the model to training mode;
# this lets it accumulate gradients and do backpropagation
total_loss = 0
for pos_rw, neg_rw in loader:
optimizer.zero_grad() # zero out the gradients to start fresh
loss = model.loss(pos_rw.to(device), neg_rw.to(device))
# compute the loss (cross-entropy)
loss.backward() # do backpropagation
optimizer.step() # updates the parameters
total_loss += loss.item() # keeps track of our total loss (it should decrease over time)
loss = total_loss / len(loader) # how wrong are we on average?
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}') # keep track of our progress
cuda
Epoch: 001, Loss: 2.9328
Epoch: 002, Loss: 1.5111
Epoch: 003, Loss: 1.1077
Epoch: 004, Loss: 0.9537
Epoch: 005, Loss: 0.8816
Epoch: 006, Loss: 0.8436
Epoch: 007, Loss: 0.8215
Epoch: 008, Loss: 0.8074
Epoch: 009, Loss: 0.7978
Epoch: 010, Loss: 0.7916
Epoch: 011, Loss: 0.7870
Epoch: 012, Loss: 0.7841
Epoch: 013, Loss: 0.7816
Epoch: 014, Loss: 0.7800
Epoch: 015, Loss: 0.7788
Epoch: 016, Loss: 0.7777
Epoch: 017, Loss: 0.7773
Epoch: 018, Loss: 0.7766
Epoch: 019, Loss: 0.7760
Epoch: 020, Loss: 0.7755
Epoch: 021, Loss: 0.7754
Epoch: 022, Loss: 0.7751
Epoch: 023, Loss: 0.7749
Epoch: 024, Loss: 0.7744
Epoch: 025, Loss: 0.7745
Epoch: 026, Loss: 0.7743
Epoch: 027, Loss: 0.7739
Epoch: 028, Loss: 0.7739
Epoch: 029, Loss: 0.7737
Epoch: 030, Loss: 0.7734
Epoch: 031, Loss: 0.7733
Epoch: 032, Loss: 0.7731
Epoch: 033, Loss: 0.7730
Epoch: 034, Loss: 0.7729
Epoch: 035, Loss: 0.7727
Epoch: 036, Loss: 0.7724
Epoch: 037, Loss: 0.7721
Epoch: 038, Loss: 0.7720
Epoch: 039, Loss: 0.7719
Epoch: 040, Loss: 0.7716
Epoch: 041, Loss: 0.7714
Epoch: 042, Loss: 0.7714
Epoch: 043, Loss: 0.7712
Epoch: 044, Loss: 0.7710
Epoch: 045, Loss: 0.7706
Epoch: 046, Loss: 0.7705
Epoch: 047, Loss: 0.7703
Epoch: 048, Loss: 0.7701
Epoch: 049, Loss: 0.7700
Epoch: 050, Loss: 0.7698
model.eval()
# set model to eval mode - this means it doesn't accumulate gradients
# and uses way less memory
z = model() # get embeddings
z_cpu = z.to('cpu').detach().numpy()
# put these on the CPU and detach it from the neural network.
Now that we’ve created embeddings from the Cambridge street network, we’ll want to figure out how useful our embeddings actually are! To do so, we’ll use a clustering algorithm. Clustering can be useful for recommendation algorithms, pattern recognition, and more. We want to partition our dataset such that objects within groups are more similar to objects in the same group than other groups – so it’s similar logic to community detection.
K-means is a popular clustering algorithm that we’ll try out today; it partitions the dataset into \(k\) clusters, and each point is assigned to the cluster whose centroid (its mean) is closest to that point. Here’s a video of K-means in action. It starts by randomly assigning centroids and then assigning each point to its closest centroid. Then, the centroid is recalculated (based on the mean of the points assigned to the cluster) and the process repeats until convergence.
import contextily as cx
from sklearn.cluster import KMeans
import matplotlib
cmap = plt.get_cmap('tab20')
plt.rcParams['figure.figsize'] = (20, 20)
adj_inv_length_kmeans = KMeans(n_clusters=20).fit(z_cpu)
geo_df["label_adj_inv_length"] = [matplotlib.colors.rgb2hex(cmap(i)) for i in adj_inv_length_kmeans.labels_]
plot = geo_df.plot(
markersize=S,
c=geo_df["label_adj_inv_length"],
)
cx.add_basemap(plot, crs=geo_df.crs.to_string())
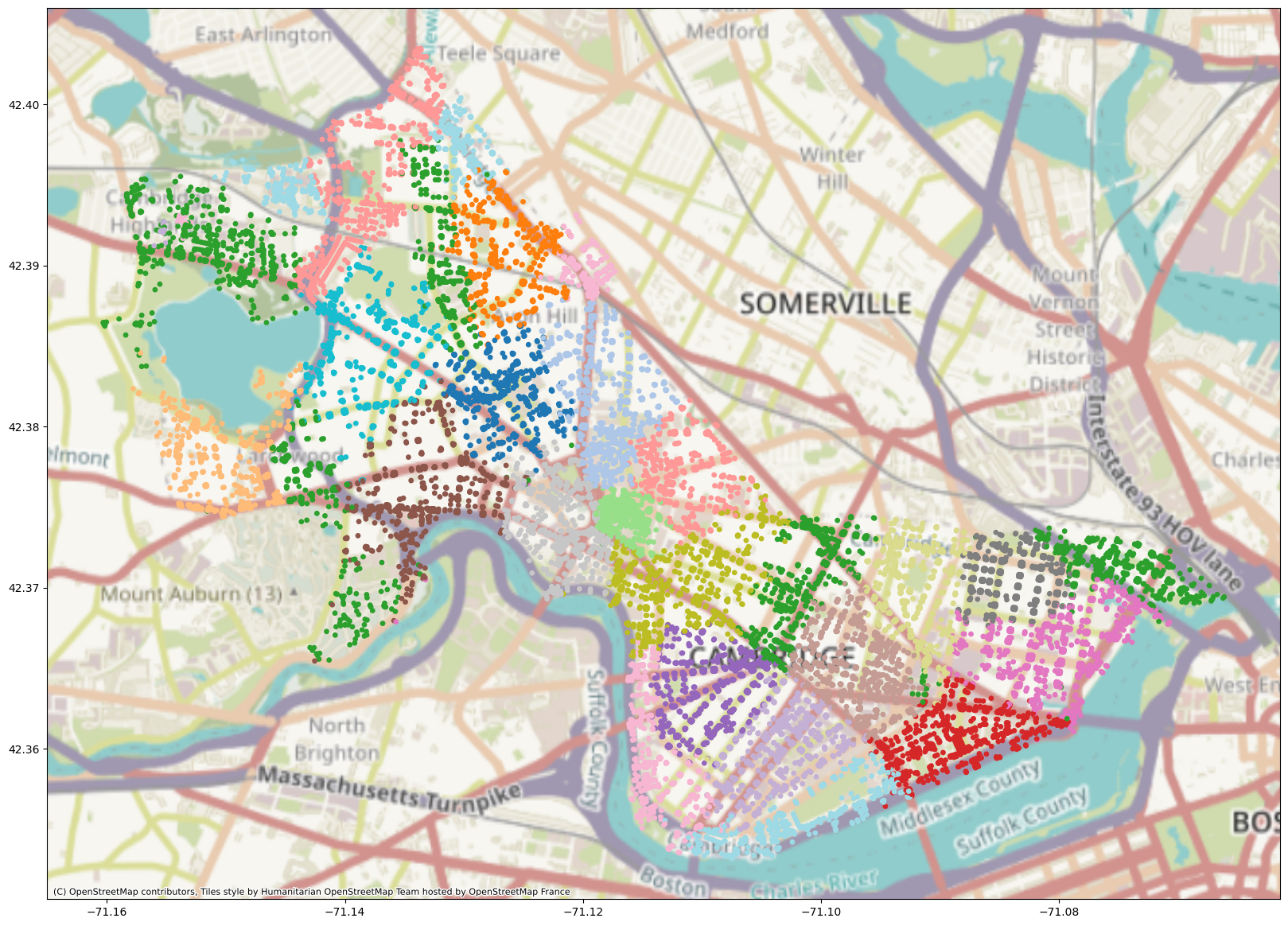
That’s pretty cool! However, Node2Vec is just the beginning of graph machine learning. We’re now going to talk about graph neural networks – neural networks that take graph data as input and learn patterns in the graph data.
What do graph neural networks (GNNs) do?#
Bottom line: GNNs learn weight matrices, just like regular neural networks. These matrices transform node attributes or embeddings. They aggregate information about a node’s neighborhood in order to make the next round of node embeddings. These embeddings can then be used for interesting downstream tasks.
Applications#
INTERACTIVE MOMENT: Let’s think of some applications for GNNs. What would you use a GNN to do?
Examples: protein-protein interaction prediction, fraud detection, or social network recommendations.
How do we learn about nodes’ neighborhoods?#
Nodes in networks notably have neighborhoods of variable size, but we want to represent all nodes with vectors of the same size. So an approach like word2vec might not work if we’re trying to aggregate information about a node’s neighborhood. Recall that we concatenated one-hot vectors representing the \(k\) words surrounding a word in a sentence to form a word’s context when training word2vec – but how do we know which \(k\) nodes ought to form the “context” of a node with far more than \(k\) neighbors?
enter…permutation-invariant functions#
What is a permutation-invariant function?#
Permutation-invariant functions take in multiple inputs (say, a list of inputs), and they produce the same output regardless of the order in which the inputs are given. So if \(f(x, y, z) = f(y, z, x)\), and so on for all orderings of \(x, y, z\), then \(f\) is permutation-invariant.
Why do we care about permutation-invariance?#
Permutation-invariance is really useful for incorporating information about a node’s neighborhood in a graph. For example, operations like the mean, maximum, sum, and minimum are all permutation-invariant. We can put in as many nodes’ attributes as we’d like, and our output will maintain the same dimensionality. It will also be insensitive to how we order the inputs, so we don’t have to worry about how to order data that doesn’t come with inherent order.
The three core functionalities in most GNNs#
AGGREGATE#
In order to pass information through a GNN, we first gather up our information about a node’s neighborhood – this might be a set of node embeddings from a previous layer or the nodes’ raw feature vectors. Then, we pass this set of vectors through a permutation-invariant function like MEAN. This aggregates our information about the node’s neighborhood into a vector of fixed length.
COMBINE#
Next, we need to update our node’s embedding. We might concatenate our neighborhood vector with our previous node embedding (or feature vector). Some GNNs will include a node in its own neighborhood during aggregation, thereby bypassing the COMBINE step. This gives us the embedding for the node that will be passed to the next layer.
READOUT#
Often we need something more than just node embeddings – we might need information about the whole graph, in which case we’ll need to apply a permutation-invariant function to our entire set of node embeddings produced by our last GNN layer, or we might need to pass individual node embeddings through some linear neural network layers to classify nodes, for example.
Today’s Fun#
Today we’re going to use a kind of graph neural network called a GCN (Graph Convolutional Network). I’ve added an in-depth mathematical description of GCNs to the Appendix of this notebook; I’d like to focus on the programming aspects of working with neural networks and graph data for today.
TL;DR: A GCN (Kipf & Welling, 2017) is a type of graph neural network that aggregates nodes’ neighborhoods in a clever way. It uses insights from image processing to perform the AGGREGATE functionality. It scales nicely (as far as GNNs go), learns about graph structure and node features, and performs quite well on graphs with node features & labels.
We’re going to practice training a GCN on the Cora dataset. Cora is a commonly used citation dataset; the task is to label ML publications by subject area based on links (citations) between publications.
import numpy as np
from torch.nn import Linear
import torch
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import CitationFull
from torch_geometric.loader import DataLoader
from torch_geometric.transforms import RandomNodeSplit
# loading the dataset
dataset = CitationFull('/courses/PHYS7332.202610/shared/data/', name='Cora')
# checking if the GPU is available; else use the CPU.
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device) # yell if you don't see 'cuda' here!
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
# we're making two GCN convolutional layers here!
self.gcn1 = GCNConv(dataset.num_features, 64)
# the first one takes in the raw node features and outputs a vector of length 64.
self.gcn2 = GCNConv(64, 16)
# the second one takes in the output of gcn1 and outputs a vector of length 16.
self.out = Linear(16, dataset.num_classes)
# then we make a one-hot vector with an entry for each class in the dataset.
def forward(self, x, edge_index):
h1 = self.gcn1(x, edge_index).relu() # we use a ReLU activation function.
h2 = self.gcn2(h1, edge_index).relu() # this indicates how data moves through the network.
z = self.out(h2)
return h2, z
splits = RandomNodeSplit(split='train_rest', num_val=0.15, num_test=0.15)(dataset.data)
# this lets us make a mask on our dataset
# such that we're only training the model on a subset of nodes.
# we have a validation set that we look at each epoch to track our accuracy
# as well as a test set that we can use to look at our performance at the end of training.
model = GCN() #instantiates our GCN
model.to(device) # puts it on the GPU
criterion = torch.nn.CrossEntropyLoss()
# cross-entropy loss tells us how wrong given our final output
optimizer = torch.optim.Adam(model.parameters(), lr=0.02)
# you can mess with the learning rate or choice of optimizer
loader = DataLoader(dataset)
for epoch in range(1, 51):
model.train() # keeps track of gradients; this is memory-intensive.
total_loss = 0 # keep track of loss
tot_accuracy = 0 # keep track of
for batch in loader:
optimizer.zero_grad()
# zero the gradient so we aren't accumulating them unnecessarily
h2, z = model(batch.x.to(device), batch.edge_index.to(device))
# make sure we're putting our data on GPU
loss = criterion(z[splits.train_mask], batch.y.to(device)[splits.train_mask])
# only do backpropagation based on nodes in the train set.
loss.backward()
# this is the backpropagation step.
optimizer.step()
# optimizers control how backpropagation goes. T
# The fancier ones, like Adam, can adjust the learning rate
# dynamically depending on the magnitude of the gradients.
# AdaGrad can change the learning rate for each rate, so it's really fancy.
total_loss += loss.item() # keep track of our total loss (cross-entropy)
model.eval() # put the model in eval mode - don't accumulate gradients.
# this saves memory!
val_h, val_z = model(dataset.x.to(device), dataset.edge_index.to(device))
# run our dataset through the model
val_z = val_z[splits.val_mask]
# look only at the validation set's vectors
ans = val_z.argmax(dim=1)
# what predictions did we get for the classes?
ys = batch.y.to(device)[splits.val_mask]
tot_accuracy += torch.mean(torch.eq(ans, ys).float()) # how often were we right?
loss = total_loss / len(loader)
accuracy = tot_accuracy / len(loader)
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}, Accuracy: {accuracy:.4f}')
cuda
/courses/PHYS7332.202610/shared/ml-env-hopefully-working/lib/python3.11/site-packages/torch_geometric/data/in_memory_dataset.py:300: UserWarning: It is not recommended to directly access the internal storage format `data` of an 'InMemoryDataset'. If you are absolutely certain what you are doing, access the internal storage via `InMemoryDataset._data` instead to suppress this warning. Alternatively, you can access stacked individual attributes of every graph via `dataset.{attr_name}`.
warnings.warn(msg)
Epoch: 001, Loss: 4.2748, Accuracy: 0.0165
Epoch: 002, Loss: 4.1549, Accuracy: 0.0505
Epoch: 003, Loss: 3.9971, Accuracy: 0.1876
Epoch: 004, Loss: 3.7546, Accuracy: 0.1738
Epoch: 005, Loss: 3.5283, Accuracy: 0.1671
Epoch: 006, Loss: 3.3456, Accuracy: 0.2327
Epoch: 007, Loss: 3.1314, Accuracy: 0.2849
Epoch: 008, Loss: 2.9415, Accuracy: 0.3425
Epoch: 009, Loss: 2.7567, Accuracy: 0.3860
Epoch: 010, Loss: 2.5565, Accuracy: 0.4362
Epoch: 011, Loss: 2.3663, Accuracy: 0.4722
Epoch: 012, Loss: 2.1951, Accuracy: 0.4998
Epoch: 013, Loss: 2.0282, Accuracy: 0.5312
Epoch: 014, Loss: 1.8785, Accuracy: 0.5544
Epoch: 015, Loss: 1.7522, Accuracy: 0.5709
Epoch: 016, Loss: 1.6255, Accuracy: 0.5776
Epoch: 017, Loss: 1.5199, Accuracy: 0.5921
Epoch: 018, Loss: 1.4267, Accuracy: 0.5958
Epoch: 019, Loss: 1.3424, Accuracy: 0.6073
Epoch: 020, Loss: 1.2561, Accuracy: 0.6117
Epoch: 021, Loss: 1.1884, Accuracy: 0.6207
Epoch: 022, Loss: 1.1326, Accuracy: 0.6309
Epoch: 023, Loss: 1.0834, Accuracy: 0.6332
Epoch: 024, Loss: 1.0323, Accuracy: 0.6356
Epoch: 025, Loss: 0.9814, Accuracy: 0.6443
Epoch: 026, Loss: 0.9338, Accuracy: 0.6511
Epoch: 027, Loss: 0.8880, Accuracy: 0.6544
Epoch: 028, Loss: 0.8490, Accuracy: 0.6561
Epoch: 029, Loss: 0.8212, Accuracy: 0.6568
Epoch: 030, Loss: 0.7861, Accuracy: 0.6642
Epoch: 031, Loss: 0.7516, Accuracy: 0.6628
Epoch: 032, Loss: 0.7247, Accuracy: 0.6612
Epoch: 033, Loss: 0.6996, Accuracy: 0.6598
Epoch: 034, Loss: 0.6705, Accuracy: 0.6655
Epoch: 035, Loss: 0.6443, Accuracy: 0.6585
Epoch: 036, Loss: 0.6261, Accuracy: 0.6618
Epoch: 037, Loss: 0.6055, Accuracy: 0.6645
Epoch: 038, Loss: 0.5796, Accuracy: 0.6686
Epoch: 039, Loss: 0.5566, Accuracy: 0.6686
Epoch: 040, Loss: 0.5352, Accuracy: 0.6699
Epoch: 041, Loss: 0.5160, Accuracy: 0.6706
Epoch: 042, Loss: 0.4985, Accuracy: 0.6713
Epoch: 043, Loss: 0.4841, Accuracy: 0.6676
Epoch: 044, Loss: 0.4713, Accuracy: 0.6716
Epoch: 045, Loss: 0.4548, Accuracy: 0.6679
Epoch: 046, Loss: 0.4356, Accuracy: 0.6706
Epoch: 047, Loss: 0.4190, Accuracy: 0.6709
Epoch: 048, Loss: 0.4081, Accuracy: 0.6686
Epoch: 049, Loss: 0.3965, Accuracy: 0.6733
Epoch: 050, Loss: 0.3822, Accuracy: 0.6726
Your Turn#
For this Your Turn section, I want you to do one or more of the following:
Figure out how to make a GCN model with an adjustable number of layers (e.g.
model = GCN(3)should give me a model that has three GCN layers). Try training the model with several different numbers of layers. Tell me how the performance changes as the number of layers increases/decreases. Optionally, look at the embeddings that the model produces and tell me if their quality changes.The GCNConv layer takes several different keyword arguments that are its own (e.g.
improved,add_self_loops,normalize) or can be inherited from the MessagePassing class intorch-geometric, as GCNConv is a message-passing GNN layer. TheMessagePassingarguments include a choice of aggregation function and the ability to change the flow of message-passing. Mess with these keyword arguments and keep track of the accuracy and loss as training proceeds for a few settings of, say, aggregation function. Plot your accuracy and/or loss over the course of training for several different settings of the parameter you chose to vary. What do you notice? Why do you think this is the case?Look at the different choices of convolutional layers available here. Choose a couple different types of convolutional layers and build models with those layers. Which do well on this dataset? Which do worse? Why do you think that is?
Appendix: Backpropagation (by request):#
At a very high level, backpropagation is how we adjust our weights, going back from the output layer (and our loss function) all the way back to the weights from the input layer.
It involves computing a bunch of partial derivatives (gradients) and adjusting our weights/biases (the parameters we’re learning in our neural network) according to the relationship between the gradients and the loss.
What ingredients do we need to do backpropagation?#
First, we need a loss function. Our loss function (or cost function) needs to be differentiable with respect to the weights and biases we use in the network. Our loss also has to be expressed as a function of the input and our weights and biases. For example, let’s look at a toy example with one hidden layer and a mean squared error (MSE) loss function.
The simplified output \(g(\vec{x})\) of our neural network with input \(\vec{x}\), given weight matrices \(W^{(1)}\) and \(W^{(2)}\) and generic activation functions \(\sigma^{(1)}\) and \(\sigma^{(2)}\), is
Our loss function, with ground truth \(\vec{z}\), is \(\lvert \lvert g(\vec{x}) - \vec{z} \rvert \rvert\). In the generalized sense, we can use a generic loss function \(C(g(\vec{x}), \vec{z})\).
Next, we need partial derivatives and the chain rule!
This is how backpropagation adjusts the weights – we compute the partial derivative of our cost function \(C\) with respect to one weight from node \(i\) to node \(j\) in the \(2^{nd}\) matrix of weights:
Here, \(y_j\) is the \(j^{th}\) output of our network (in the output layer).
In other words, we’re passing the dot product of row \(j\) of \(W^{(2)}\) and \(\vec{h}\), our hidden layer’s output, through a sigmoid function. Let’s call \(\sum_{i}w^{(2)}_{ij} * h_i\) \(o_j\), and let’s expand our partial derivative expression using the chain rule once more.
What are we doing here? We’re tracing how our specific weight \(w^{(2)}_{ij}\) affects our computed loss for a particular input (or batch of inputs).
We know that \(\frac{\delta y_j}{o_j}\) is the partial derivative of the activation function \(\sigma^{(2)}\).
Additionally, we know that \(\frac{o_j}{\delta w^{(2)}_{ij}}\) is
Only one term in this sum relies on \(w^{(2)}_{ij}\) – that’s \(w^{(2)}_{ij} h_i\). This means this part of our partial derivative reduces to
Now let’s look at \(\frac{\delta y_j}{h_j}\). Let’s say we’re using a sigmoid activation function; in this case, this part of our partial derivative is
If we’re using MSE for the loss function \(C\) and \(\vec{z}\) is our ground truth answer,
Therefore, the gradient of our loss with respect to \(w^{(2)}_{ij}\) is
Moving right along/TL;DR (For those who hate math!!)#
We take partial derivatives with the chain rule to figure out how much our loss function changes with respect to a particular parameter (like a weight or bias) in the neural network.
Then we can change that specific weight with this information. We usually have a learning rate \(\eta\) (or an optimizer that governs the learning rate, which is fancier) that tells us how much to change a weight/bias with respect to our computed gradient.
We don’t want to update our parameters too much based on any one example, which is why the learning rate tends to be pretty small (much less than 1) and optimizers will lower the learning rate as training goes on and the model gets better at its task.
Let’s review how backpropagation works by watching this video.
GCNs (as an example of a GNN)#
Material in this section relies heavily on Maxime Labonne’s blog post in Towards Data Science and Thomas Kipf’s blog post on his GitHub website.
A GCN (Kipf & Welling, 2017) is a type of graph neural network that aggregates nodes’ neighborhoods in a clever way. It uses insights from image processing to perform the AGGREGATE functionality. It scales nicely (as far as GNNs go), learns about graph structure and node features, and performs quite well on graphs with node features & labels.
What is a convolution in image processing world?#
A convolution matrix, or kernel, is used in image processing to blur, enhance, sharpen, or detect edges in an image. It’s a small matrix (relative to the size of the image) that is applied to each pixel in the image and its neighbors within a certain distance.
The generic equation for a kernel is this, where \(\omega\) is the kernel matrix, \(a\) and \(b\) indicate the dimensions of the kernel, and \(f(x, y)\) is the \((x, y)^{th}\) pixel of the image:
Here, \(g(x, y)\) is the \((x, y)^{th}\) pixel of the output image.
Here’s a visual example of a convolution matrix being applied to a single pixel (from this primer on CNNs by Zafir Nasim):
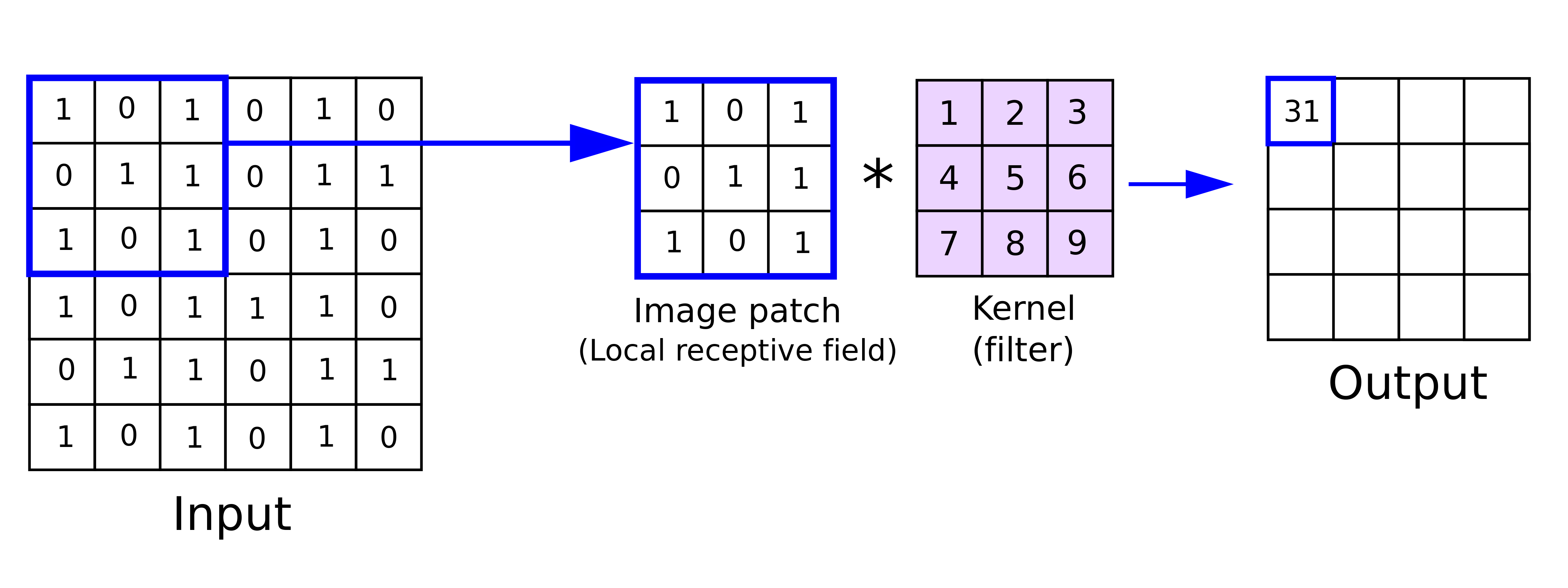
Graph Convolutions#
You might say, cool, that’s neat, but how does that apply to graphs? First of all, graph neighborhoods are not rectangular in shape, and graphs notably have degree distributions - not every node has the same number of neighbors (far from it)!
Let’s tackle what happens in GCNs at the node level first. We’ll look at how we create our first embedding for node \(i\), \(h_{i}^{(1)}\).
We know we need to merge our node features with those of our neighbors, so we define a node \(i\)’s neighborhood here as \(i\)’s neighbors plus \(i\) itself. We’ll denote this as \(\tilde{N_i}\).
In the simplest case, we could create a weight matrix \(W_i\) and multiply each node \(j\)’s features \(x_j\) by \(W_i\), then sum them:
This seems neat, but there’s a small problem.
INTERACTIVE MOMENT: Nodes in graphs notably don’t all have the same degree. What’s going to happen to the vectors of high-degree nodes as compared to those of low-degree nodes right now? How might we fix this?
Spoiler alert: we’re going to divide by \(k_i\), the degree of node \(i\). This keeps vector magnitudes around the same-ish size.
However, there’s one more improvement we can make. Kipf and Welling noticed that features from high-degree nodes tended to propagate through the network more easily than those from low-degree nodes. They therefore up-weight the lower-degree nodes’ contributions in the following way:
INTERACTIVE MOMENT: Why does this work?
Matrix Formulation#
There’s also a neat way we can formulate this as a matrix multiplication. Here, \(\hat{A}\) is the adjacency matrix with self-loops added, and \(\hat{D}\) is \(\hat{A}\)’s degree matrix (i.e. \(A + I\)). \(H^{(l)}\) is the matrix of node embeddings coming into layer \(l\), and \(W^{(l)}\) is the weight matrix of layer \(l\):
Next time…#
Class 16: Dynamics on Networks 1 — Diffusion and Random Walks class_16_dynamics1
References and further resources:#
Class Webpages
Jupyter Book: https://network-science-data-and-models.github.io/phys7332_fa25/README.html
Github: https://github.com/network-science-data-and-models/phys7332_fa25/
Syllabus and course details: https://brennanklein.com/phys7332-fall25